
졸업프로젝트로 무엇을 할까 고민하던 중, 참여하고 있던 오픈채팅에서 겪었던 불편함이 생각났다. 톡방의 규모가 커지면 한번에 이야기 하는 사람들도 많고, 동시에 오가는 주제도 많았다. 그러다 보면, 내가 이야기 하는 주제에 집중하거나 팔로업하기가 조금 쉽지 않은 감이 있었다.
요새 LLM도 엄청나게 발전했으니, 이를 잘만 이용하면 채팅 속에서 주제들을 찾고, 이를 바탕으로 분류하여 내가 보고싶은 주제의 메시지들만 볼 수 있지 않을까 생각했다. 그래서 이것을 졸업프로젝트의 주제로 하여 개발하기 시작했다.
GPT 를 사용하면 조금 더 편하게 할 수 있을 것이라 생각했고, 테스트해본 결과 성능이 나쁘지 않게 나왔다. 하지만, 그렇게 돈으로 쉽게 해결하면 졸업프로젝트의 취지와는 맞지 않다는 조언을 들었고, 적어도 분류하는 부분에서는 직접 모델을 구현하거나, 직접 만들어낸 아이디어를 바탕으로 개발하는 쪽으로 노선을 잡았다.
임베딩(Embedding)은 단어나 문장을 하나의 벡터로 매핑시키는 것을 말한다. 적어도, 문장 내의 단어들은 독립적이지 않고, 맥락을 공유해야 한다고 생각하여 Transformer 를 사용한 임베딩 모델을 이용하고자 결심했다.
Bert도 이용해볼까 생각했는데, 이미 결제해놓은 OpenAI 크레딧이 있어서 OpenAI의 text-embedding-3-small 모델을 이용하게 되었다.
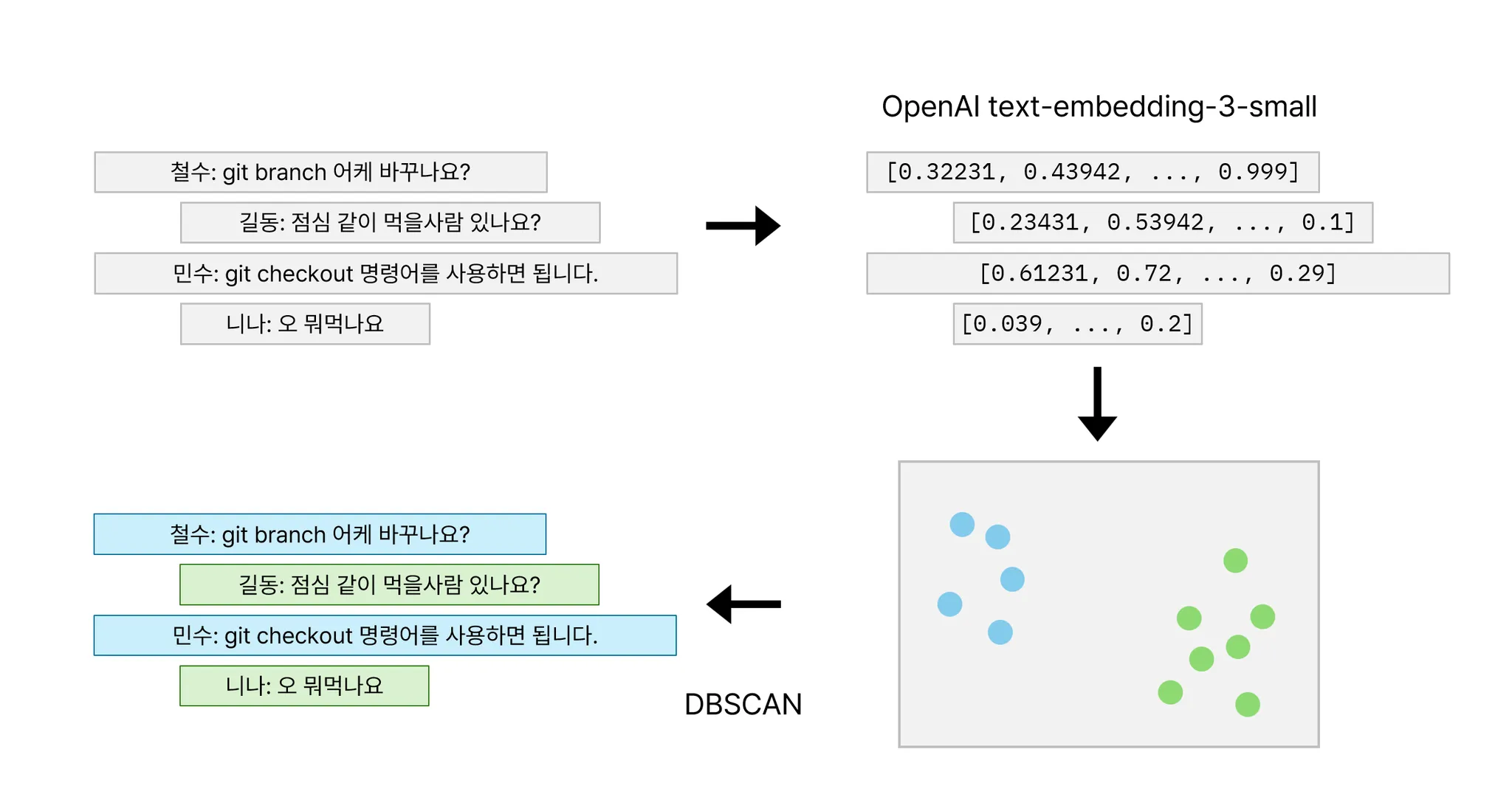 클러스터링 방법
클러스터링 방법
처음 구상한 방법은 이렇게 각각의 채팅들을 임베딩하여, DBSCAN 과 같은 클러스터링 알고리즘으로 분류하는 아주 초보적인 아이디어였다.
OpenAI 의 임베딩 벡터는 크기(norm)가 1이기 때문에, 두 벡터의 내적을 구하면 간단히 코사인 유사도를 구할 수 있었다. 따라서, DBSCAN 의 metric 으로도 코사인 거리를 사용하였다.
하지만, 단순히 메시지 내용만 가지고는 적절하게 주제에 따른 분류가 되지 않을 것이라 판단하여, 채팅에서 중요한 발화자와 시간 정보를 추가하여 유사도를 비교하였다.
발화자는 같으면 0, 다르면 1을 반환하게 하였고, 시간은 상대적인 차를 거리로 했다.
따라서, 번째 채팅과 번째 채팅의 거리 를 다음과 같이 가중평균으로 계산되도록 설정하였다.
임베딩 api 를 한번 호출하는데에는 약 0.5초가 걸렸는데, 각 채팅에 대한 임베딩을 얻기 위해 api 를 여러번 호출하는 것이 아닌, 배치로 호출하여 모델의 수행 시간을 대폭 줄일 수 있었다.
client = OpenAI(api_key='...')
# 베치 입력 지원
def get_embedding(text_array, model='text-embedding-3-small'):
embedded_text = client.embeddings.create(input=text_array, model=model).data
result = torch.tensor([message.embedding for message in embedded_text])
return result
def encode_chats(chats):
messages = [chat[MESSAGE_KEY] for chat in chats]
embed_messages = get_embedding(messages) # 메시지의 배열을 입력으로
encoded_chats = [{
EMBED_KEY: msg,
USER_KEY: chat[USER_KEY],
TIME_KEY: chat[TIME_KEY],
} for msg, chat in zip(embed_messages, chats)]
return encoded_chats
하지만, 당연하게도 분류 성능이 좋진 않았다.
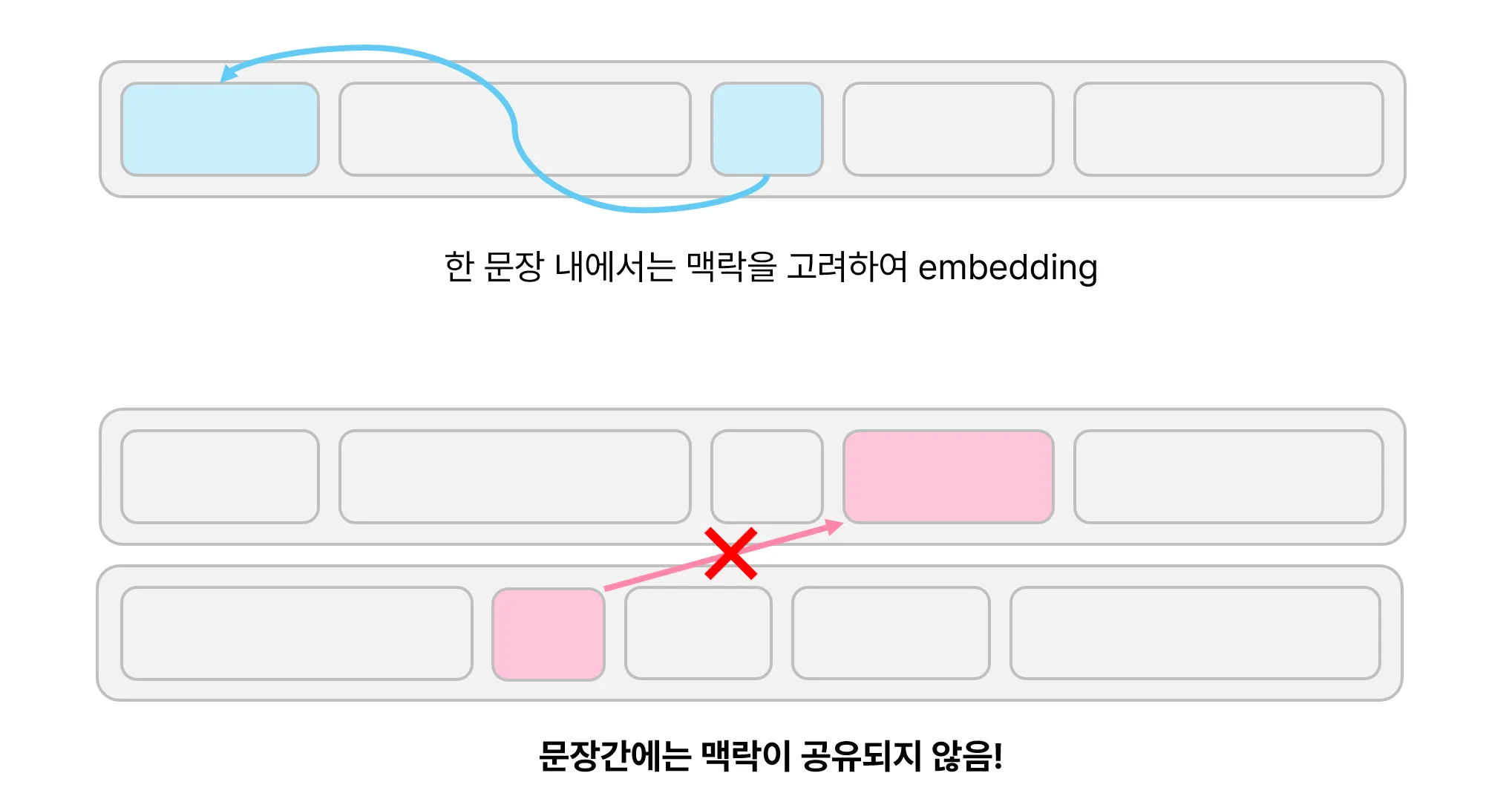 문장 간 맥락
문장 간 맥락
본 모델은 각각의 채팅을 따로 임베딩하고, 그것들을 클러스터링 하는 방식이다.
그러다보니, 문장 내에서는 맥락이 고려되지만 문장 간에는 맥락이 공유되지 않았다. 결과적으로 문장 간에는 비슷한 단어들이 있어야만 같은 군집으로 묶였다. 따라서, 다음과 같은 이어지는 대화는 제대로 한 클러스터로 군집화되지 않았다.
- 점심 같이 먹을사람 있나요?
- 오 어디가나요?
이를 해결하기 위해서 문장들을 concat 하여 임베딩을 하는 방식을 생각했다. 즉, 번째 메시지를 임베딩 할 때, 1번째 메시지부터 번째 메시지까지 합친 것을 임베딩 하는 것이었다. 하지만, 이는 뒤로 갈 수록 원래 임베딩하려고 했던 메시지의 의미가 희석되는 결과를 낳아, 오히려 더욱 좋지 않은 성능을 보여주었다.
DBSCAN 의 파라미터인 minPts, eps 또한 문제였다. 조금만 바꾸어도 아예 분류가 되지 않는 상황이 발생했다.
생각해본 원인 중 하나로, 임베딩의 차원이 너무 고차원이어서 거리들이 비슷비슷할 수도 있겠다는 생각을 하였다. 따라서, PCA 와 같은 차원 축소 방법을 이용해도 봤지만 문제점이 드라마틱하게 개선되지는 않았다.
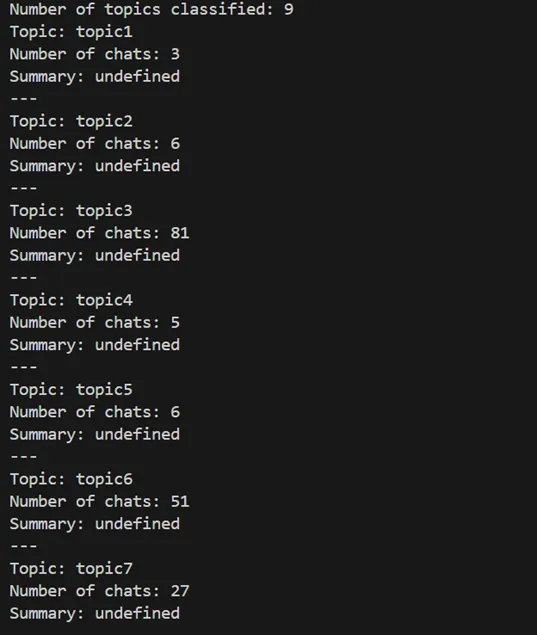 eps 0.6일 때
(eps = 0.6)
eps 0.6일 때
(eps = 0.6)
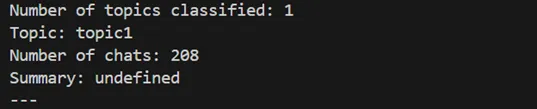 eps 0.61일 때
(eps = 0.61)
eps 0.61일 때
(eps = 0.61)
실제로 minPts = 2 로 고정한 후, eps 의 값을 0.1 만 변경시켜도 모두 하나의 클러스터로 군집화되는 것을 확인할 수 있었다.
또한, 채팅 데이터에 따라 최적인 파라미터가 천차만별이라, 실제로 사용하기에는 무리가 있다고 판단하였다.
마찬가지로 가중치 () 도 최적의 값을 찾기 힘들었다.
차라리 이렇게 결정하기 힘든 가중치(파라미터)들을 학습시켜볼까? 하는 생각도 들었다.
DBSCAN 의 적절한 파라미터를 찾는데 도움을 줄 수 있는 OPTICS 를 활용한다. 이것을 자동화 할 수 있을까?
최적의 가중치를 고르기 어려우니, 이를 학습할 수 있는 모델로 바꾸어서 학습한다.
먼저, 메시지, 유저, 시간 정보를 모두 담은 벡터로 각 채팅을 표현한다.
여기서, 유저는 one-hot encoding 으로, 시간도 비슷하게 일정 개수의 구간으로 나누어 인코딩한다.
그리고 어떠한 채팅을 기준으로 삼아, 그 이후의 채팅들이 같은 주제인지 (코사인 유사도, 혹은 뭔가 채팅간 유사도를 나타낼 수 있는 것) 판별한다. 결국 이진 분류 문제가 되기 때문에 구현 자체는 어렵지 않을 것이라 생각했다. (성능은 별개의 문제)
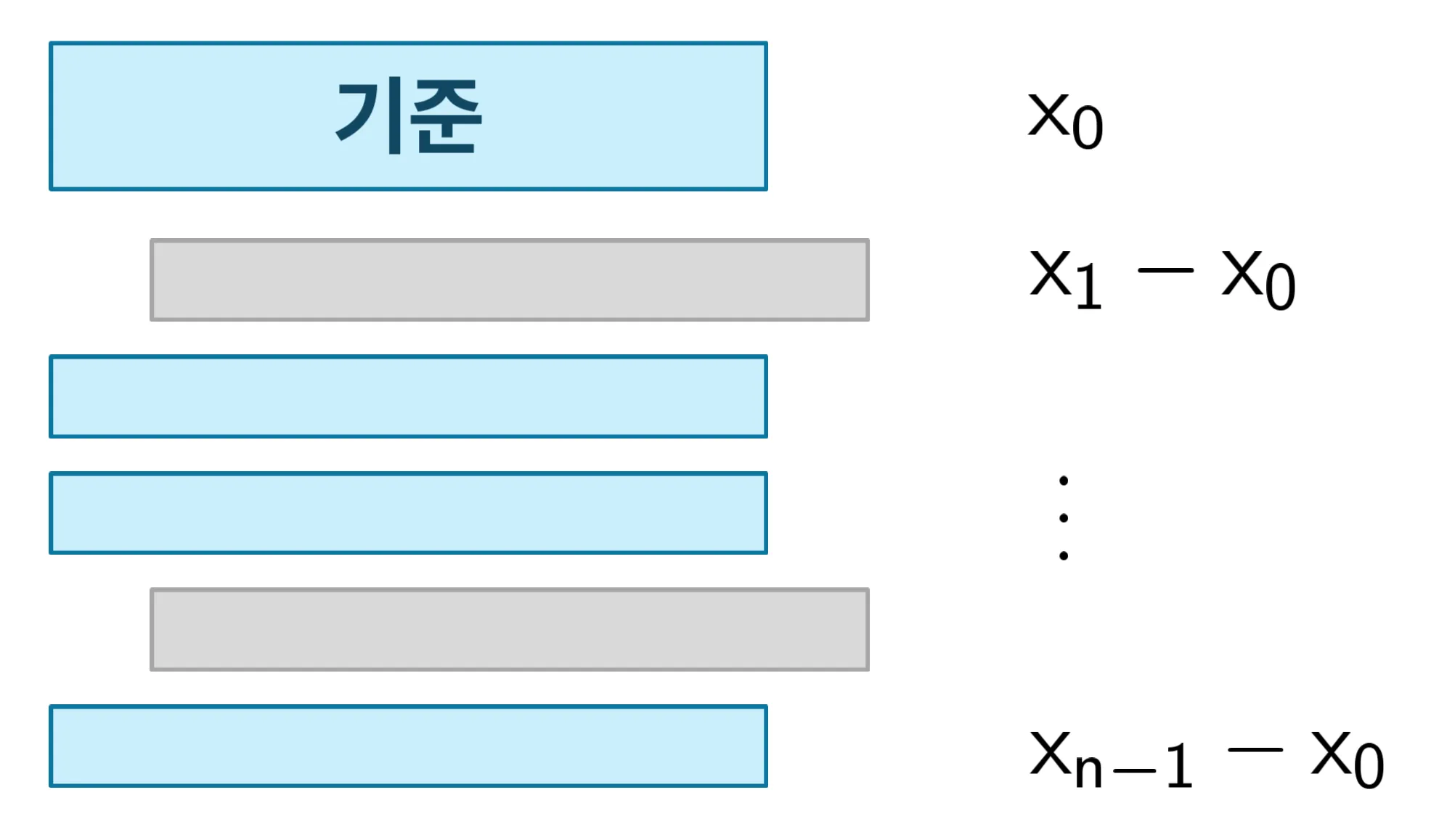 예상도
(예상도)
예상도
(예상도)
Nope. 아직 타협은 이르다.
아무튼, 일단은 그나마 가능성이 있어보이는 지도학습 같은 방향으로도 시도해 보아야겠다는 결심을 하게 되었다.
일단 교수님의 피드백을 받았다. 단순한 클러스터링은 무리인 것 같고, Multi-turn(혹은 multi-session, multi-party) 관련 논문을 찾아보라는 것이 그것이었다.
그래서 여러 논문을 찾아보던 도중, Context-Aware Conversation Thread Detection in Multi-Party Chat 을 발견하였다.
Context-Aware Conversation Thread Detection, 줄여서 CATD 모델은 채팅과 같은 multi-turn 상황의 메시지들이 주어졌을 때, 이 안에서 같은 주제를 가지는 메시지들을 찾아내고 분류하는 방법이다.
먼저, 스레드라는 개념이 중요한데, 같은 주제의 메시지들의 배열을 의미한다. 같은 스레드에서는 시간 순서로 정렬되어 있고, 각 스레드는 독립적이다. 아마 레딧↗을 써본 사람이라면 쉽게 알 수 있을 것이다.
 레딧의 스레드
(레딧의 한 스레드)
레딧의 스레드
(레딧의 한 스레드)
CATD 에서도 이 개념을 사용한다. 학습하면서 실시간으로 기존의 스레드들과 비교를 하고, 그중에 가장 적합한 스레드에 현재 메시지를 할당하거나, 혹은 새로운 스레드를 만드는 식이다.
구체적인 모델을 설명하기 이전에 사용되는 변수에 대해 설명하면;
-
- 번째 까지의 메세지들
-
- 번째 메세지()의 label. 즉, 어떤 thread에 속하는지.
-
- 번째 주제에 속하는 메세지들을 모아놓은 집합. ex)
-
- 번째까지의 메세지 중 번째 주제에 속하는 메세지들의 집합. 즉,
- 여기서 는 주제 에 속하는 메세지 중 마지막에서 번째의 인덱스를 의미.
- ex) 에서
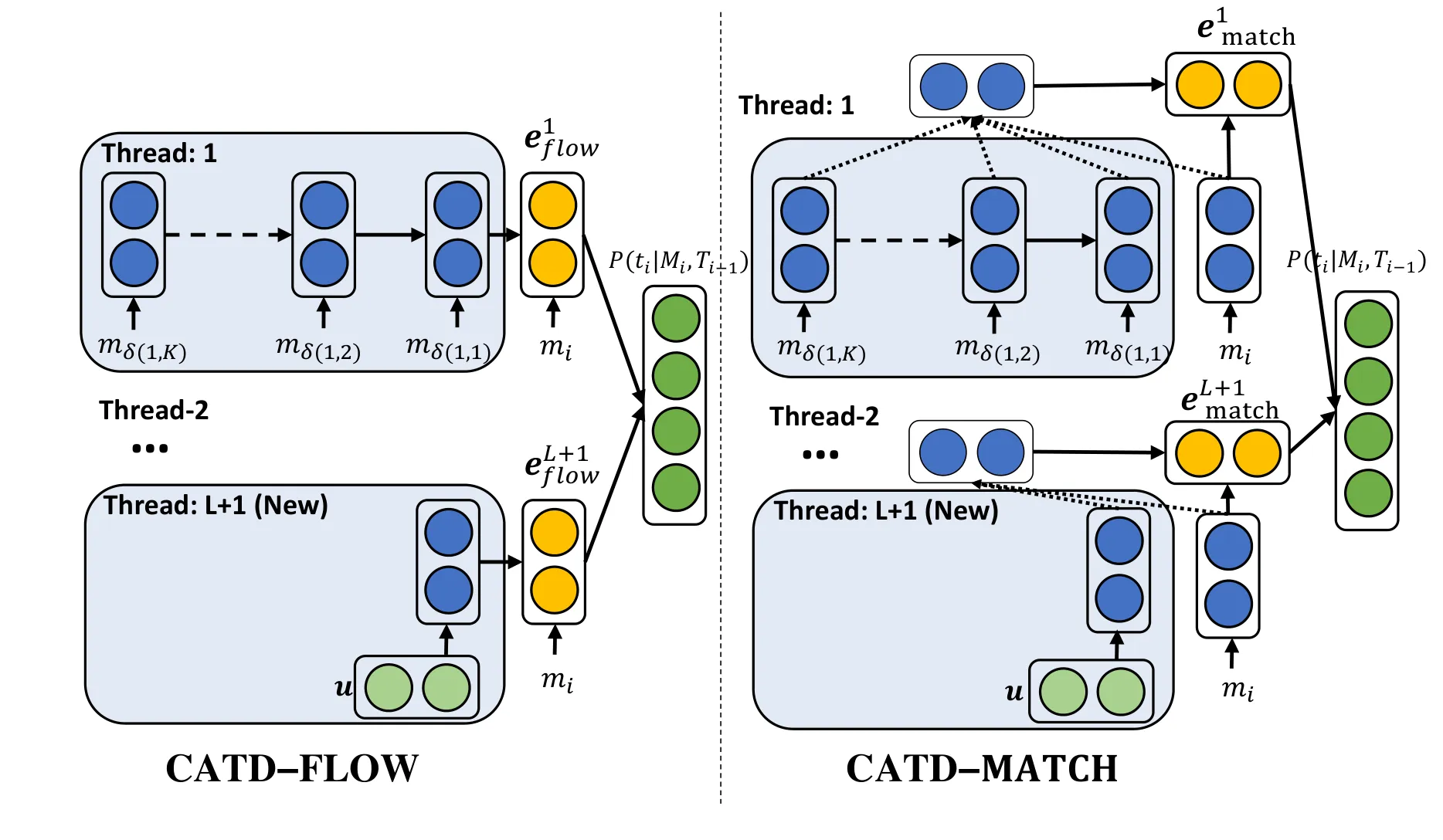 CATD 모델
CATD 모델
FLOW 는 현재 메시지가 어떤 스레드(혹은 새로운 스레드)에 가장 잘 이어지는지 판단하는 모델이다.
구체적으로는, L 개의 스레드가 주어졌을 때, 각 스레드의 가장 최신 K 개의 메시지와 현재 메시지를 LSTM 의 입력으로 넣고, 그것의 최종 출력을 logit 으로 하여 softmax 레이어에 통과시켜 다중 분류하는 방식이다. 새로운 스레드에 대해서는 라는 파라미터를 도입하여 동일하게 LSTM 에 통과시켜 판단한다.
MATCH 는 현재 메시지가 어떠한 스레드와 가장 의미적으로 유사한지 판단하는 모델이다.
구체적으로는 FLOW 와 비슷하게 각 스레드에서 최신 K 개의 메시지를 LSTM 의 입력으로 넣고, 그것의 출력들에 새로운 메세지를 어텐션 해준다. 새로운 스레드에 대한 처리도 FLOW 와 같다.
논문에서는 CATD-COMBINE 이라고 해서, 두 모델을 gate combination 하는 것도 소개하였다. 따라서, 기본적으로 두 방법을 융합한 COMBINE 모델을 사용하였다.
이를 이용한 전반적인 학습 과정은 다음과 같다.
-
텍스트 임베딩 생성 및 발화자, 시간 정보 인코딩
OpenAI 의 text-embedding-3-small 모델을 이용하여 메세지를 1536 차원의 벡터로 임베딩하고, 유저와 시간 정보를 인코딩하여 하나의 벡터로 만든다.
-
LSTM 기반의 모델을 이용하여 분류
-
분류 함수를 이용해서 어떤 스레드에 속할지 확인
-
loss 계산 및 파라미터 업데이트
다음은 모델을 코드로 구현한 것이다.
class CATD_FLOW(nn.Module):
def __init__(self, input_dim, hidden_dim, k, dropout=0, num_layers=1):
super(CATD_FLOW, self).__init__()
self.k = k
self.lstm = nn.LSTM(input_dim, hidden_dim, batch_first=True, dropout=dropout, num_layers=num_layers)
self.fc = nn.Linear(hidden_dim, 1)
self.u = nn.Parameter(torch.randn(1, 1, input_dim)) # L+1 스레드를 위한 파라미터.
def forward(self, message, threads):
new_threads = [*threads, self.u]
e_flow_list = []
for thread in new_threads:
if (thread.size(1) > self.k):
thread = thread[:, -self.k:, :] # 최근 k 개의 메세지만 선택
# thread 와 새로운 메세지 결합
new_message = message[None, None, :]
thread_input = torch.cat([thread, new_message], dim=1)
_, (h_thread, _) = self.lstm(thread_input)
e_flow = torch.squeeze(h_thread[-1]) # LSTM 의 마지막 hidden state. (hidden_dim, )
out = e_flow
e_flow_list.append(out)
return torch.stack(e_flow_list)
class CATD_MATCH(nn.Module):
def __init__(self, input_dim, hidden_dim, k, dropout=0, num_layers=1):
super(CATD_MATCH, self).__init__()
self.k = k
self.lstm = nn.LSTM(input_dim, hidden_dim, batch_first=True, dropout=dropout, num_layers=num_layers)
self.fc = nn.Linear(hidden_dim, 1)
self.u = nn.Parameter(torch.randn(1, 1, input_dim)) # L+1 스레드를 위한 파라미터.
def forward(self, message, threads):
new_threads = [*threads, self.u]
e_match_list = []
message_batched = message[None, None, :] # (1, 1, input_dim) 으로 차원 변환
for thread in new_threads:
if (thread.size(1) > self.k):
thread = thread[:, -self.k:, :] # 최근 k 개의 메세지만 선택
lstm_output, _ = self.lstm(thread)
_, (h_message, _) = self.lstm(message_batched)
# 하나의 배치만 선택
lstm_output_unbatched = lstm_output[-1]
h_message_unbatched = h_message[-1].squeeze()
# 가장 message와 유사한 스레드의 메세지를 선택 (attention)
attention_score = torch.softmax(lstm_output_unbatched @ h_message_unbatched, dim=0)
e_cxt = attention_score @ lstm_output_unbatched
e_match = F.normalize(e_cxt, dim=0) * F.normalize(h_message_unbatched, dim=0)
out = e_match
e_match_list.append(out)
return (torch.stack(e_match_list), h_message_unbatched)
class CATD_COMBINE(nn.Module):
def __init__(self, input_dim, hidden_dim, k):
super(CATD_COMBINE, self).__init__()
self.flow_model = CATD_FLOW(input_dim, hidden_dim, k)
self.match_model = CATD_MATCH(input_dim, hidden_dim, k)
self.w = nn.Parameter(torch.randn(hidden_dim))
self.fc = nn.Linear(hidden_dim, 1)
def forward(self, message, threads):
e_flows = self.flow_model(message, threads)
e_matches, h_hat = self.match_model(message, threads)
# Gate 계산
g_input = F.normalize(e_matches, dim=-1) - F.normalize(h_hat, dim=0)
g = torch.sigmoid(g_input @ self.w)[:, None]
e_combines = (1 - g) * e_matches + g * e_flows
out = torch.tanh(self.fc(e_combines))
return out
CATD 모델은 기본적으로 지도학습이다. 즉, 정답 레이블이 필요하고, 이를 맞추는데 초첨이 되어있다.
그래서, 우리의 의도는 맥락이 바뀌는 것을 잘 캐치하는 것이었는데, 오히려 단순히 정답 레이블만 맞추는 모습을 보였다. 즉, a 스레드 → b 스레드 로 바뀌는 것 에서 a, b 가 무슨 숫자인지는 상관없이 학습을 하길 기대했지만, 그렇지 못했다는 것이다.
학습 데이터도 부족하다보니 자연스럽게 오버피팅도 발생하였고, 결국 그다지 만족할만한 성능을 보이지 못했다.
물론 그러한 학습 데이터 및 정답 레이블을 일일이 정하는 것 자체도 고역이었다.
분류의 민감도를 조절하는 하이퍼파라미터가 단 하나였다. 그래서, 채팅마다 천차만별의 결과를 보여도 이를 수동적으로 튜닝하기가 무척 어려웠다.
결론적으로 보았을 때, CATD 모델은 그렇게 좋은 성능을 보이진 못했다. 또한, 지도학습에서 오는 학습 데이터 구성의 어려움, 민감도 조절의 힘듦 등으로 인해 비지도 학습으로 다시 옮겨가야겠다는 생각을 하게 되었다.
하지만, 분명히 얻어간 것도 있었다. 바로, 스레드(thread) 개념이었는데, 순차적으로 매 메시지가 할당될 스레드를 계산하고 정하는 방식이 이후 방법에 큰 영향을 주었다. 또한, 비단 맥락의 유사성만 보는 것이 아닌 전체적인 의미적 유사성(cos 유사도…)도 고려하는 편이 좋은 성능을 낼 수 있다는 것을 알게 되었다.
BERT 의 학습법으로 NSP(Next Sentence Prediction) 가 있다. 즉, 말 그대로 두 문장이 연결되는 문장인지 학습하는 것인데, 잘 학습된 모델을 이용하면 지금까지의 방법 보다 좋은 성능을 낼 수 있을 것이라 생각했다.
NSP 를 적용한 모델은 놀랍게도 성능이 꽤 괜찮았다. 이전에는 전혀 분류하지 못하던 대화들도 이제는 어느정도 분류할 수 있게 되었다. 대화의 맥락을 최대한 파악하게끔 스레드와 윈도우의 개념을 접목시켰는데, 입력으로 주어지는 두 문장을 다음과 같이 구성했다.
- 해당 스레드의 채팅 메세지 개를 concat 한 문장
- 현재 채팅 메세지
모델은 해당 스레드에 속할 확률()을 반환하도록 하였다.
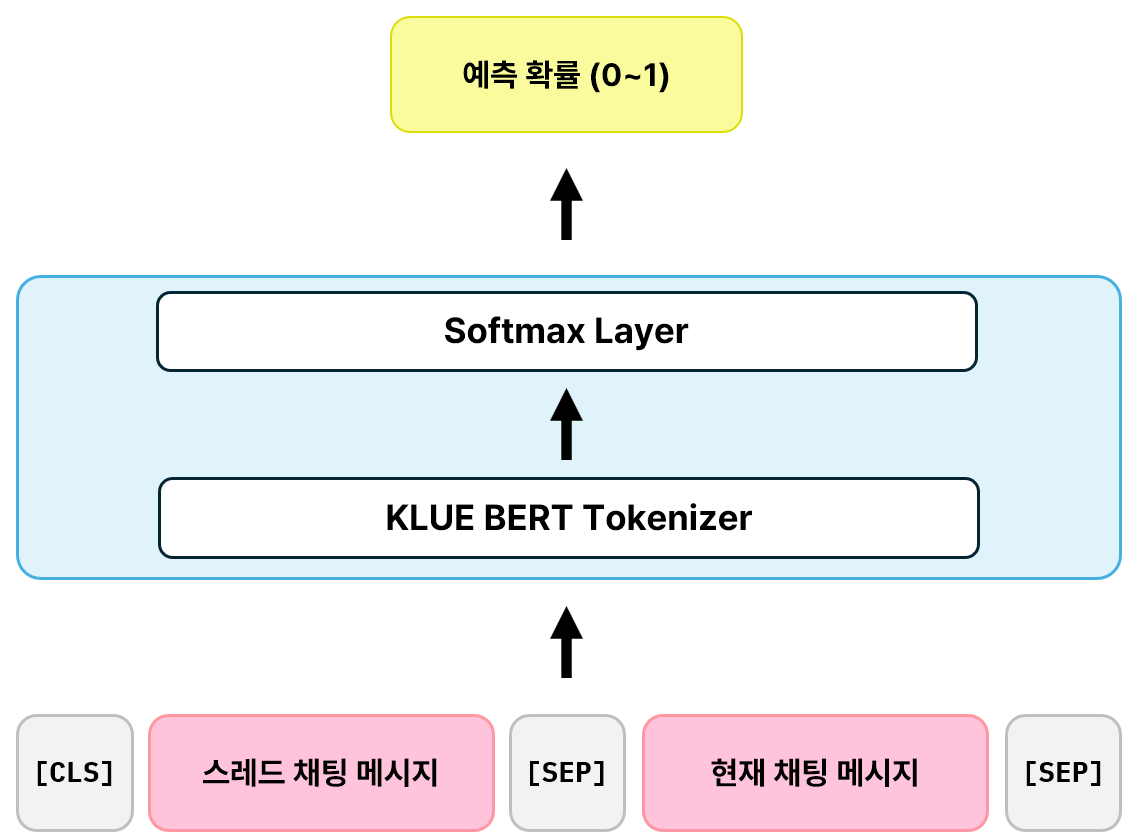 NSP 모델
NSP 모델
하지만, NSP 만으로는 부족했다. 스레드 전체의 의미 유사성보다는 얼마나 잘 이어지는지만 보았기 때문에 의미적으로 덜 유사한 채팅이더라도 “질문 - 대답” 과 같이 잘 이어지면 높은 확률을 반환했다. 따라서, 의미적인 유사성 또한 캐치하기 위해 SBERT 를 추가적으로 이용했다.
SBERT 를 통과시켜 얻은 인코딩된 두 문장의 코사인 유사도를 계산하는 식으로 확률()을 도출하였다.
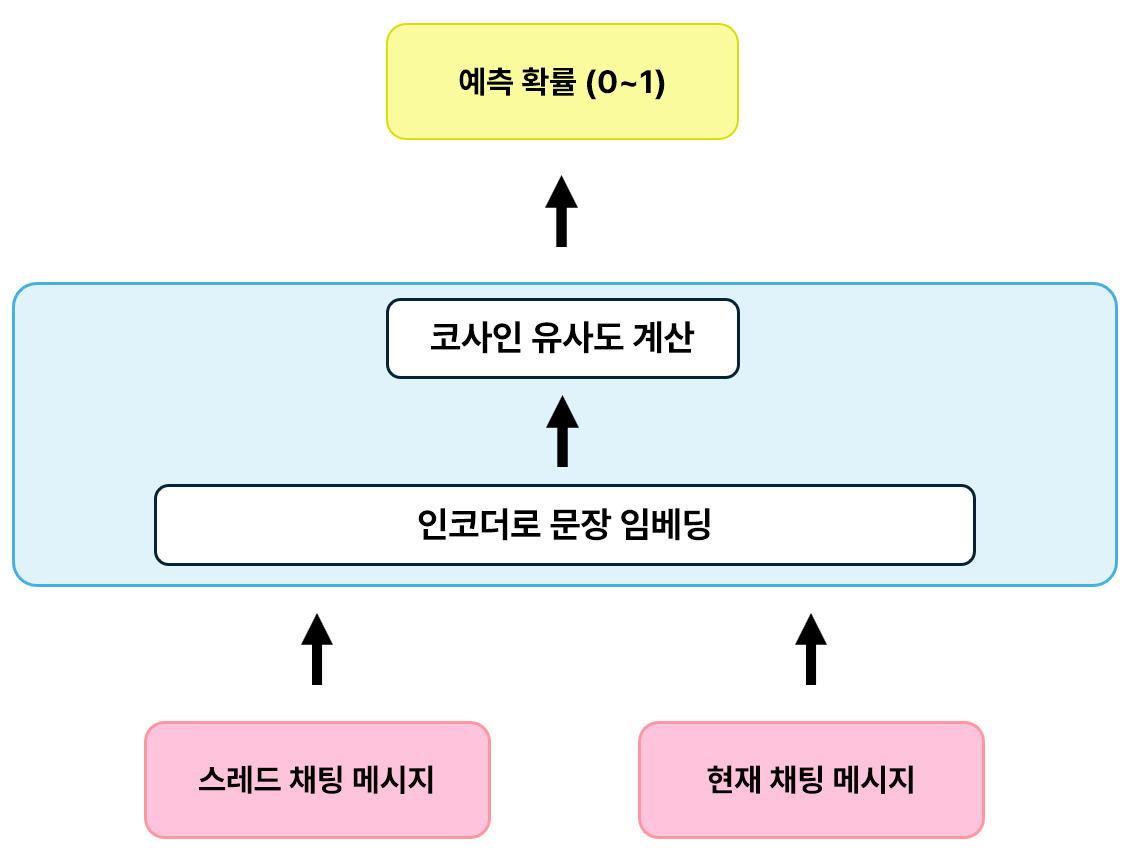 SBERT 모델
SBERT 모델
또한, 추가적으로 다음과 같은 사항들을 고려했다.
- 시간 가중치()를 지수함수 형태로 구성
- 1분 내 같은 사람이 말하면 높은 가중치
- 스레드 타임아웃 (12시간)
- 스레드의 마지막 채팅으로부터 12시간이 지나면, 아무리 의미적으로 유사해도 새로운 스레드로 분류할 수 있도록 하였다
- empirical result
- 두 글자 이하의 무의미한 단어는 제외하였다.
- e.g. 헉, 앗…
- 이모티콘, 사진, 동영상은 제외하였다.
- 초성으로 된 문자(ㅋㅋㅋ, ㅎㅎ)는 제외하였다.
- 하이퍼파라미터 튜닝을 통해 상대적으로 안정적인 threshold 를 도출했다.
- 민감도를 조절할 수 있도록, 유저가 선택할 수 있는 UI 를 제공하였다.